|
Vineet Jain |
|
|
I am a Ph.D. candidate at
McGill University and
Mila,
supervised by Siamak Ravanbakhsh.
I have spent time at Valence Labs and Bosch Center for Artificial Intelligence.
Before starting my Ph.D., I earned an M.S. in Machine Learning from Carnegie Mellon University and a B.Tech. from the Indian Institute of Technology Kharagpur. During my undergraduate studies I spent two inspiring summers at Mila, supervised by Yoshua Bengio, and at the Laboratory of Computational Neuroscience at EPFL, supervised by Wulfram Gerstner. If you want to chat about my research, or you are interested in a collaboration, please send me an email! |

|
Publications |

|
Recursive Self-Aggregation Unlocks Deep Thinking in Large Language Models
Siddarth Venkatraman*, Vineet Jain*, Sarthak Mittal*, Vedant Shah, Johan Obando-Ceron, Yoshua Bengio, Brian R. Bartoldson, Bhavya Kailkhura, Guillaume Lajoie, Glen Berseth, Nikolay Malkin, Moksh Jain Preprint
abstract /
bibtex /
pdf
Test-time scaling methods improve the capabilities of Large Language Models (LLMs) by increasing the amount of compute used during inference to make a prediction. Inference-time compute can be scaled in parallel by choosing among multiple independent solutions or sequentially through self-refinement. We propose Recursive Self-Aggregation (RSA), a test-time scaling method inspired by evolutionary methods that combines the benefits of both parallel and sequential scaling. Each step of RSA refines a population of candidate reasoning chains through aggregation of subsets to yield a population of improved solutions, which are then used as the candidate pool for the next iteration. RSA exploits the rich information embedded in the reasoning chains -- not just the final answers -- and enables bootstrapping from partially correct intermediate steps within different chains of thought. Empirically, RSA delivers substantial performance gains with increasing compute budgets across diverse tasks, model families and sizes. Notably, RSA enables Qwen3-4B-Instruct-2507 to achieve competitive performance with larger reasoning models, including DeepSeek-R1 and o3-mini (high), while outperforming purely parallel and sequential scaling strategies across AIME-25, HMMT-25, Reasoning Gym, LiveCodeBench-v6, and SuperGPQA. We further demonstrate that training the model to combine solutions via a novel aggregation-aware reinforcement learning approach yields significant performance gains. Code is available here.
@article{venkatraman2025recursive,
title={Recursive Self-Aggregation Unlocks Deep Thinking in Large Language Models},
author={Venkatraman, Siddarth and Jain, Vineet and Mittal, Sarthak and Shah, Vedant and Obando-Ceron, Johan and Bengio, Yoshua and Bartoldson, Brian R and Kailkhura, Bhavya and Lajoie, Guillaume and Berseth, Glen and others},
journal={arXiv preprint arXiv:2509.26626},
year={2025}
}
|
|
Diffusion Tree Sampling: Scalable inference-time alignment of diffusion models
Vineet Jain, Kusha Sareen, Mohammad Pedramfar, Siamak Ravanbakhsh NeurIPS, 2025
abstract /
bibtex /
pdf
Adapting a pretrained diffusion model to new objectives at inference time remains an open problem in generative modeling. Existing steering methods suffer from inaccurate value estimation, especially at high noise levels, which biases guidance. Moreover, information from past runs is not reused to improve sample quality, resulting in inefficient use of compute. Inspired by the success of Monte Carlo Tree Search, we address these limitations by casting inference-time alignment as a search problem that reuses past computations. We introduce a tree-based approach that samples from the reward-aligned target density by propagating terminal rewards back through the diffusion chain and iteratively refining value estimates with each additional generation. Our proposed method, Diffusion Tree Sampling (DTS), produces asymptotically exact samples from the target distribution in the limit of infinite rollouts, and its greedy variant, Diffusion Tree Search (DTS$^\star$) performs a global search for high reward samples. On MNIST and CIFAR-10 class-conditional generation, DTS matches the FID of the best-performing baseline with up to $10\times$ less compute. In text-to-image generation and language completion tasks, DTS$^\star$ effectively searches for high reward samples that match best-of-N with up to $5\times$ less compute. By reusing information from previous generations, we get an anytime algorithm that turns additional compute budget into steadily better samples, providing a scalable approach for inference-time alignment of diffusion models.
@article{jain2025dts,
title={Diffusion Tree Sampling: Scalable inference-time alignment of diffusion models},
author={Jain, Vineet and Sareen, Kusha and Pedramfar, Mohammad and Ravanbakhsh, Siamak},
journal={arXiv preprint arXiv:2506.20701},
year={2025}
}
|
|
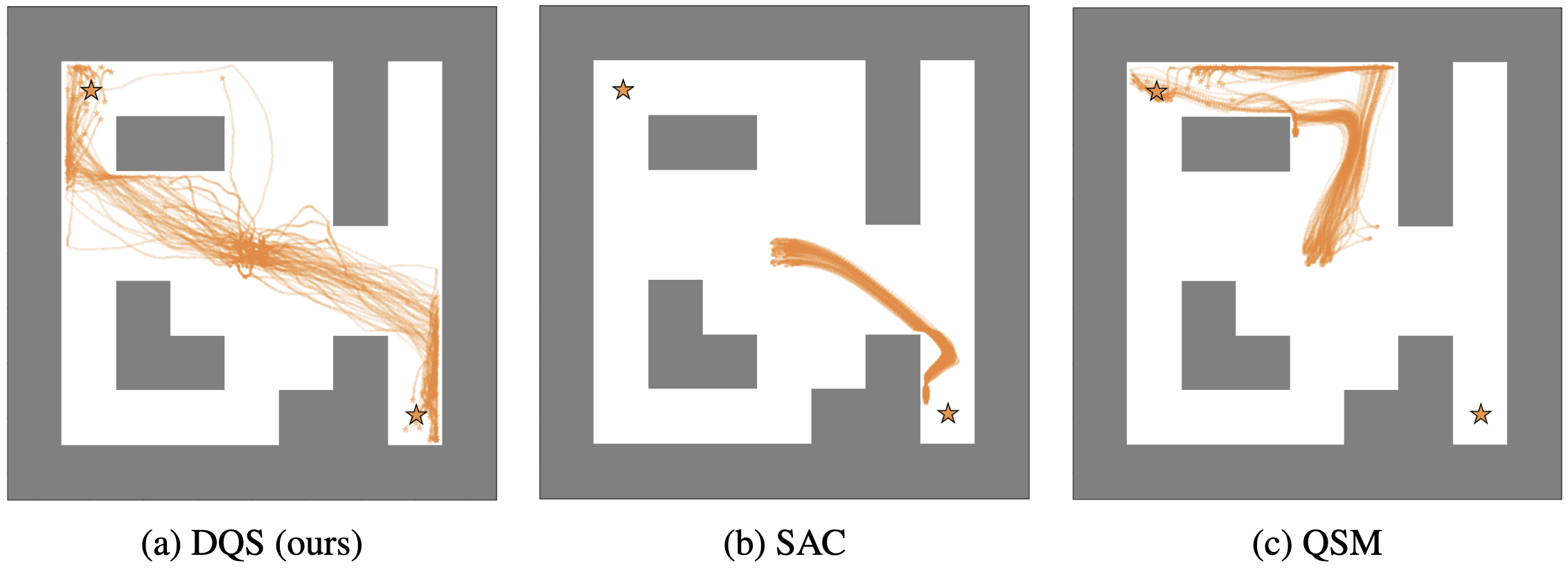
|
Sampling from Energy-based Policies using Diffusion
Vineet Jain, Tara Akhound-Sadegh, Siamak Ravanbakhsh RLC 2025 Generative Models for Robot Learning Workshop, ICLR 2025
abstract /
bibtex /
pdf
Energy-based policies offer a flexible framework for modeling complex, multimodal behaviors in reinforcement learning (RL). In maximum entropy RL, the optimal policy is a Boltzmann distribution derived from the soft Q-function, but direct sampling from this distribution in continuous action spaces is computationally intractable. As a result, existing methods typically use simpler parametric distributions, like Gaussians, for policy representation - limiting their ability to capture the full complexity of multimodal action distributions. In this paper, we introduce a diffusion-based approach for sampling from energy-based policies, where the negative Q-function defines the energy function. Based on this approach, we propose an actor-critic method called Diffusion Q-Sampling (DQS) that enables more expressive policy representations, allowing stable learning in diverse environments. We show that our approach enhances exploration and captures multimodal behavior in continuous control tasks, addressing key limitations of existing methods.
@article{jain2024sampling,
title={Sampling from Energy-based Policies using Diffusion},
author={Jain, Vineet and Akhound-Sadegh, Tara and Ravanbakhsh, Siamak},
journal={arXiv preprint arXiv:2410.01312},
year={2024}
}
|
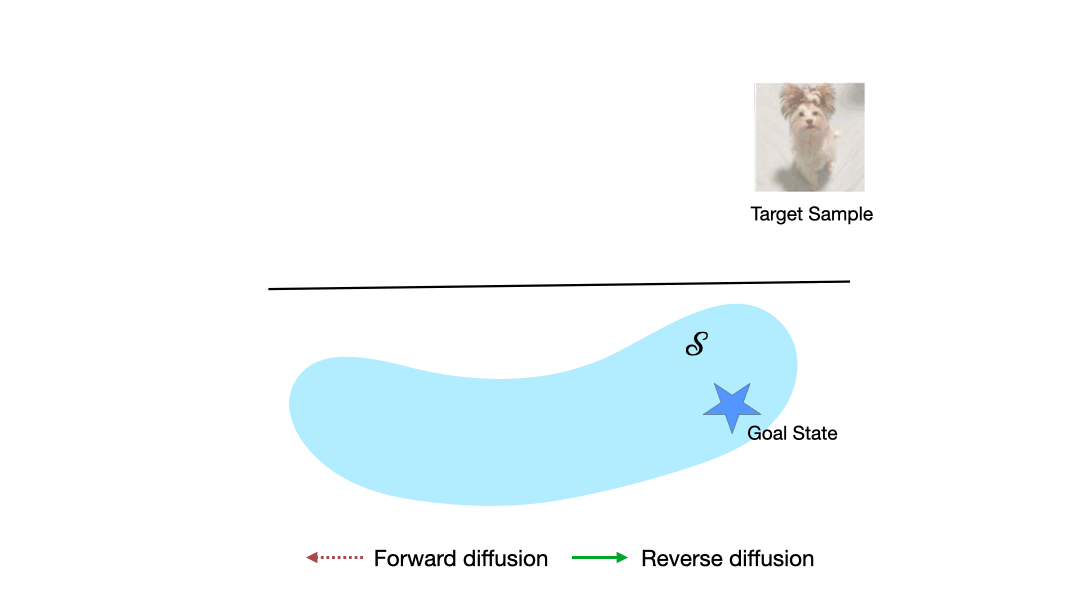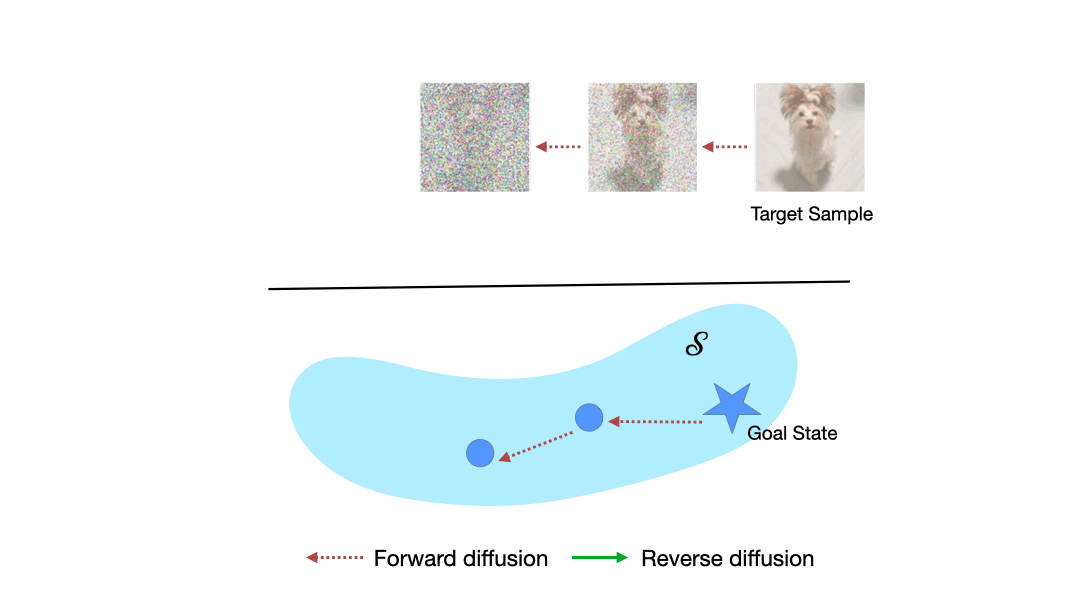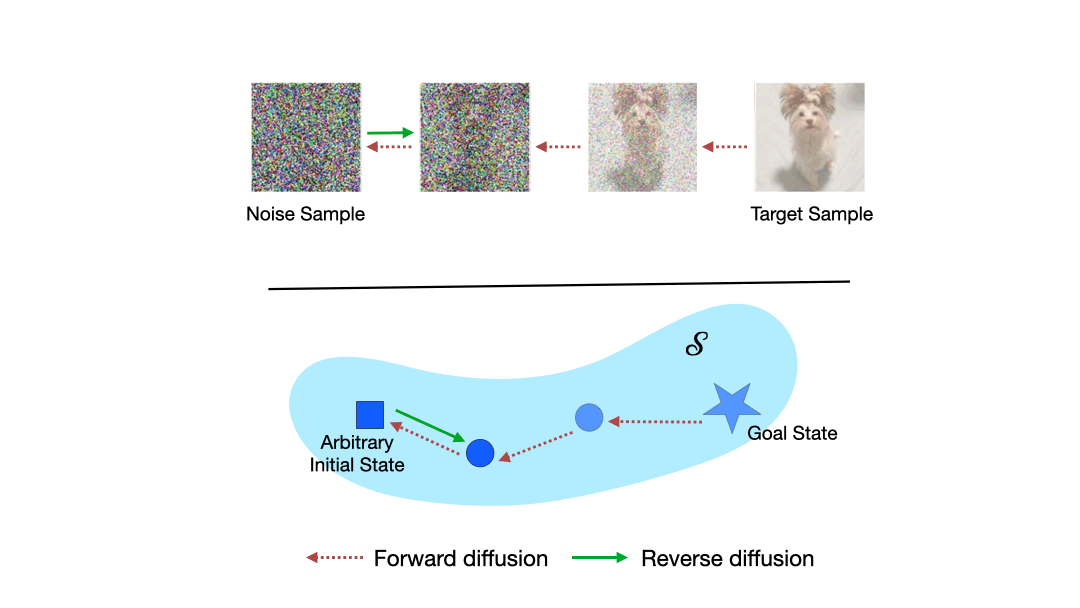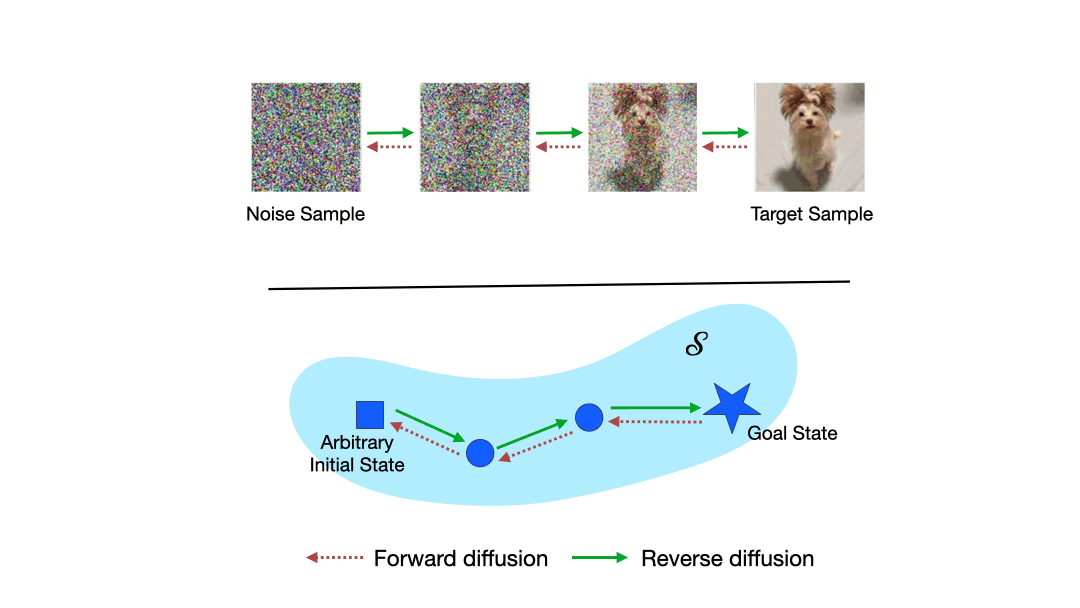
|
Learning to Reach Goals via Diffusion
Vineet Jain, Siamak Ravanbakhsh ICML 2024 Generative Models for Decision Making Workshop, ICLR 2024
abstract /
bibtex /
pdf
Diffusion models are a powerful class of generative models capable of mapping random noise in high-dimensional spaces to a target manifold through iterative denoising. In this work, we present a novel perspective on goal-conditioned reinforcement learning by framing it within the context of diffusion modeling. Analogous to the diffusion process, where Gaussian noise is used to create random trajectories that walk away from the data manifold, we construct trajectories that move away from potential goal states. We then learn a goal-conditioned policy analogous to the score function. This approach, which we call Merlin, can reach predefined or novel goals from an arbitrary initial state without learning a separate value function. We consider three choices for the noise model to replace Gaussian noise in diffusion - reverse play from the buffer, reverse dynamics model, and a novel non-parametric approach. We theoretically justify our approach and validate it on offline goal-reaching tasks. Empirical results are competitive with state-of-the-art methods, which suggests this perspective on diffusion for RL is a simple, scalable, and effective direction for sequential decision-making.
@article{jain2023learning,
title={Learning to Reach Goals via Diffusion},
author={Jain, Vineet and Ravanbakhsh, Siamak},
journal={arXiv preprint arXiv:2310.02505},
year={2023}
}
|
|
On Diffusion Modeling for Anomaly Detection
Victor Livernoche*, Vineet Jain*, Yashar Hezaveh, Siamak Ravanbakhsh ICLR 2024 (Spotlight)
abstract /
bibtex /
pdf
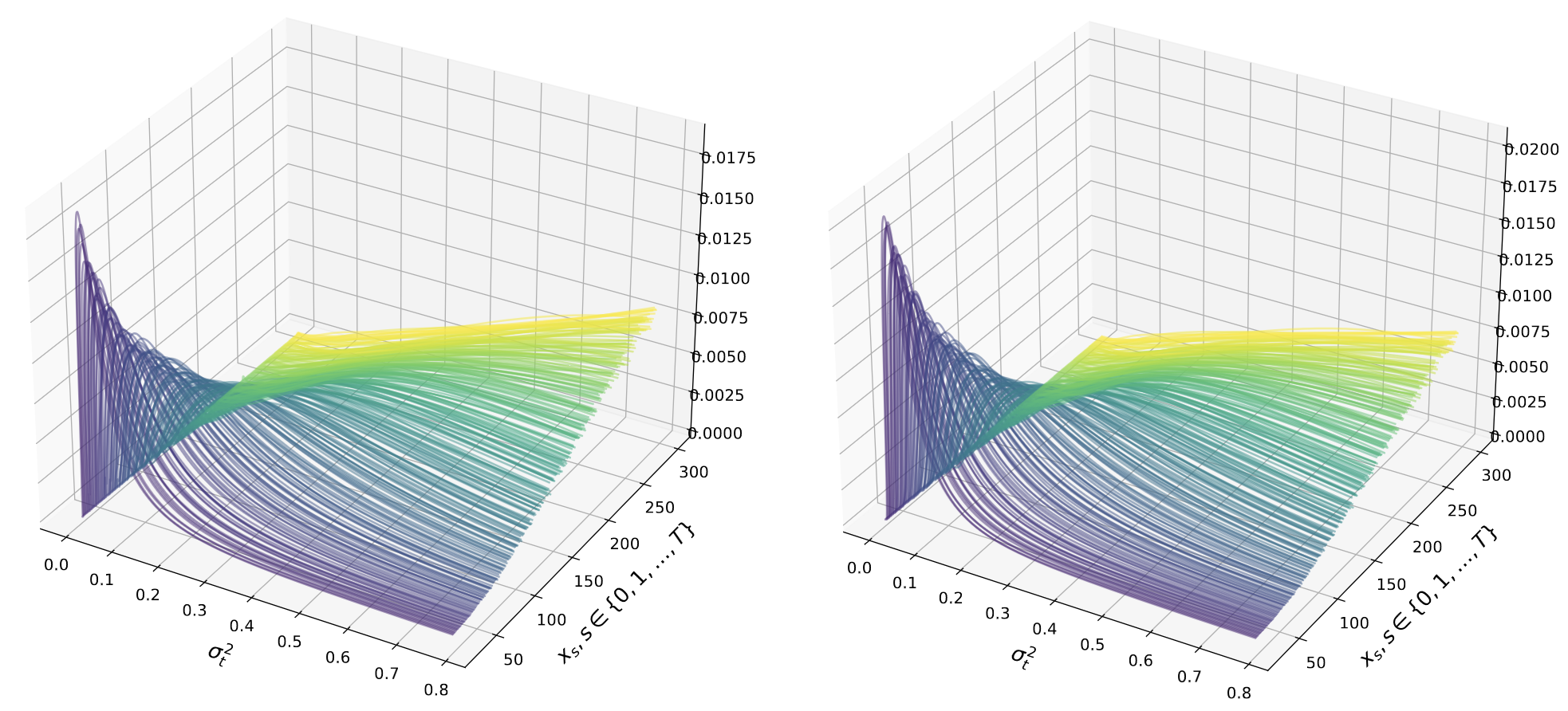
Known for their impressive performance in generative modeling, diffusion models are attractive candidates for density-based anomaly detection. This paper investigates different variations of diffusion modeling for unsupervised and semi-supervised anomaly detection. In particular, we find that Denoising Diffusion Probability Models (DDPM) are performant on anomaly detection benchmarks yet computationally expensive. By simplifying DDPM in application to anomaly detection, we are naturally led to an alternative approach called Diffusion Time Estimation (DTE). DTE estimates the distribution over diffusion time for a given input and uses the mode or mean of this distribution as the anomaly score. We derive an analytical form for this density and leverage a deep neural network to improve inference efficiency. Through empirical evaluations on the ADBench benchmark, we demonstrate that all diffusion-based anomaly detection methods perform competitively for both semi-supervised and unsupervised settings. Notably, DTE achieves orders of magnitude faster inference time than DDPM, while outperforming it on this benchmark. These results establish diffusion-based anomaly detection as a scalable alternative to traditional methods and recent deep-learning techniques for standard unsupervised and semi-supervised anomaly detection settings.
@article{livernoche2023diffusion,
title={On Diffusion Modeling for Anomaly Detection},
author={Livernoche, Victor and Jain, Vineet and Hezaveh, Yashar and Ravanbakhsh, Siamak},
journal={arXiv preprint arXiv:2305.18593},
year={2023}
}
|
|
EqR: Equivariant Representations for Data-Efficient Reinforcement Learning
Arnab Kumar Mondal, Vineet Jain, Kaleem Siddiqi, Siamak Ravanbakhsh ICML 2022
abstract /
bibtex /
pdf /
code
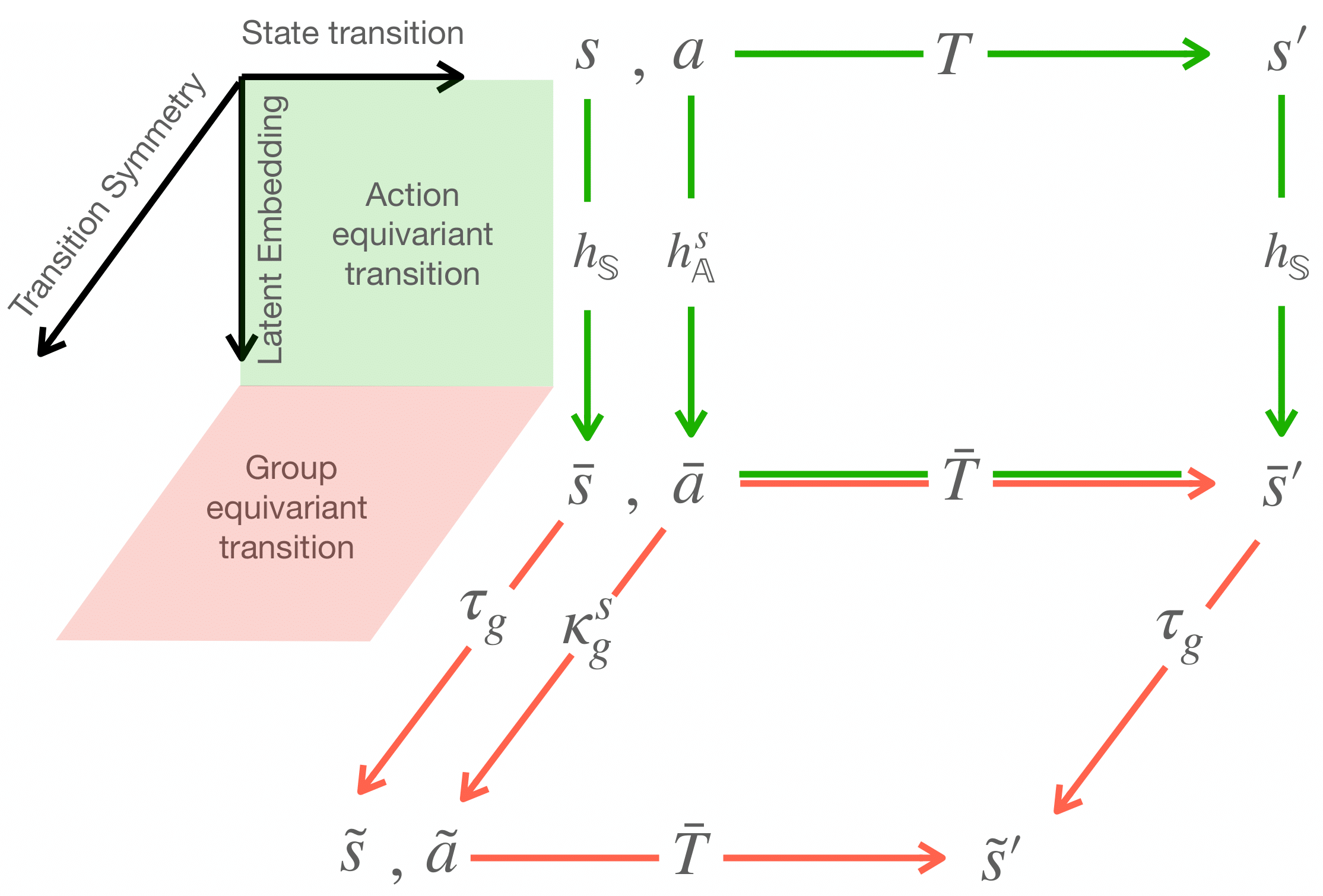
We study a variety of notions of equivariance as an inductive bias in Reinforcement Learning (RL). In particular, we propose new mechanisms for learning representations that are equivariant to both the agent's action, as well as symmetry transformations of the state-action pairs. Whereas prior work on exploiting symmetries in deep RL can only incorporate predefined linear transformations, our approach allows non-linear symmetry transformations of state-action pairs to be learned from the data. This is achieved through 1) equivariant Lie algebraic parameterization of state and action encodings, 2) equivariant latent transition models, and 3) the incorporation of symmetry-based losses. We demonstrate the advantages of our method, which we call Equivariant representations for RL (EqR), for Atari games in a data-efficient setting limited to 100K steps of interactions with the environment.
@inproceedings{mondal2022eqr,
title={Eqr: Equivariant representations for data-efficient reinforcement learning},
author={Mondal, Arnab Kumar and Jain, Vineet and Siddiqi, Kaleem and Ravanbakhsh, Siamak},
booktitle={International Conference on Machine Learning},
pages={15908--15926},
year={2022},
organization={PMLR}
}
|
|
Mini-batch Similarity Graphs for Robust Image Classification
Arnab Kumar Mondal*, Vineet Jain*, Kaleem Siddiqi BMVC 2021
abstract /
bibtex /
pdf /
code
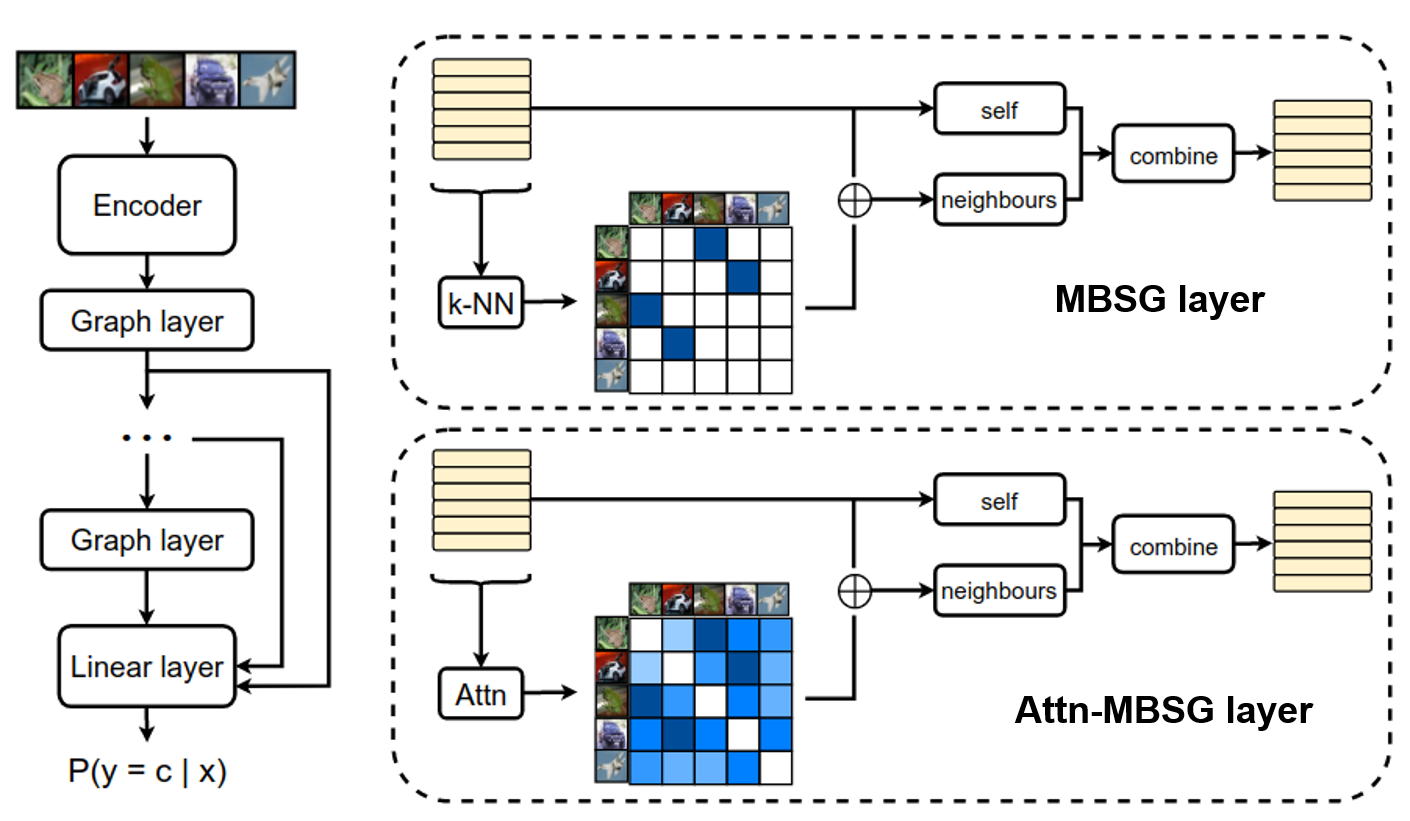
Current deep learning models for image-based classification tasks are trained using mini-batches. In the present article, we show that exploiting similarity between samples in each mini-batch can significantly boost robustness to input perturbations, an often neglected consideration in the computer vision community. To accomplish this, we dynamically construct a similarity graph from the mini-batch samples and aggregate information using an attention module. Our experiments demonstrate an increase in robustness to local noise and black-box adversarial perturbations, when compared against a baseline model. Our approach also improves performance in diverse image-based object and scene classification tasks, when compared against baseline models and competitive recent methods.
@article{mondal2012mini,
title={Mini-batch Similarity Graphs for Robust Image Classification},
author={Mondal, Arnab and Jain, Vineet and Siddiqi, Kaleem},
year={2012}
}
|
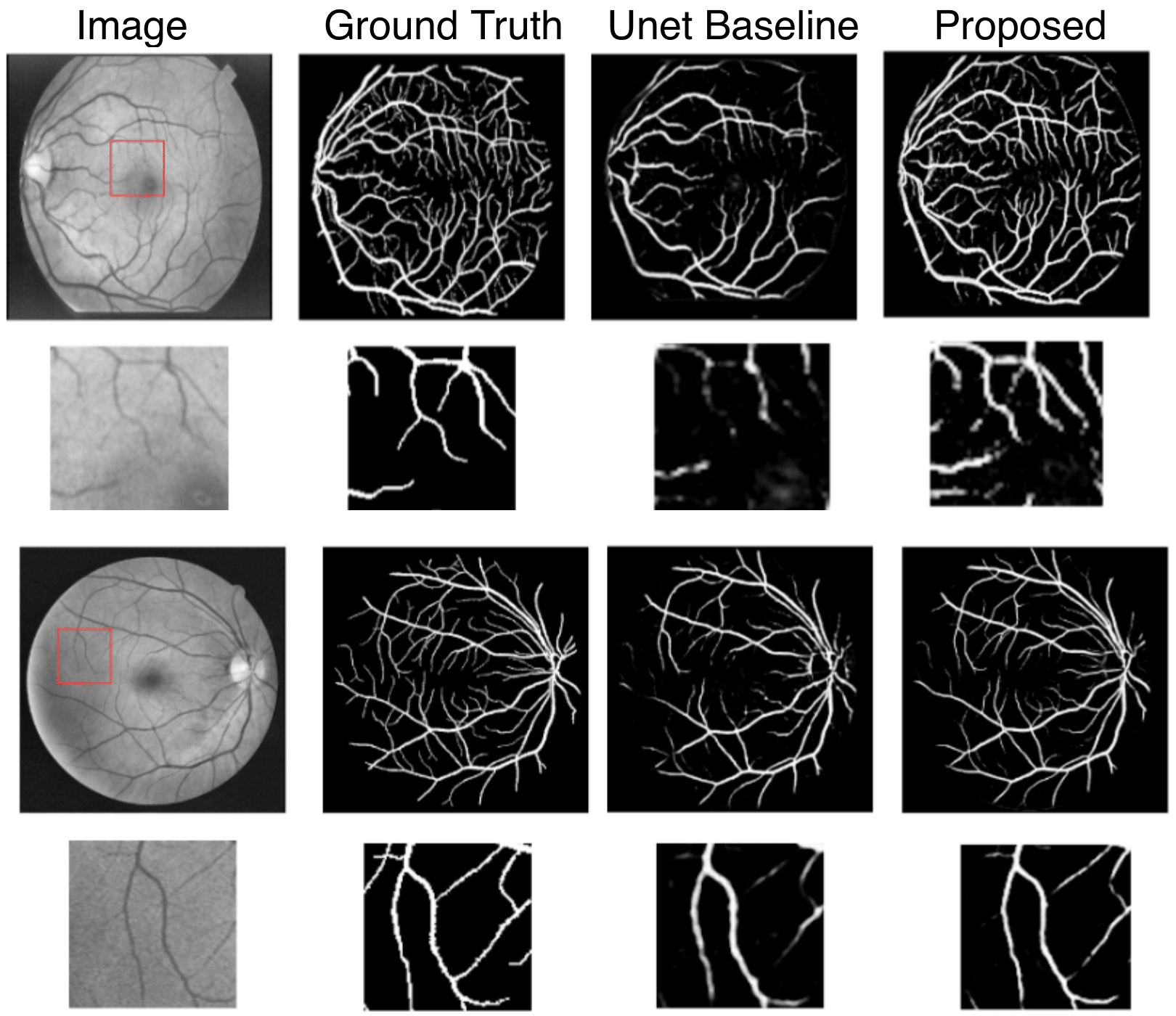
|
Retinal Vessel Segmentation Under Extreme Low Annotation: A Gan Based Semi-Supervised Approach
Avisek Lahiri*, Vineet Jain*, Arnab Kumar Mondal*, Prabir Kumar Biswas ICIP 2020
abstract /
bibtex /
pdf /
Contemporary deep learning based medical image segmentation algorithms require hours of annotation labor by domain experts. These data hungry deep models perform sub-optimally in the presence of limited amount of labeled data. In this paper, we present a data efficient learning framework using the recent concept of Generative Adversarial Networks; this allows a deep neural network to perform significantly better than its fully supervised counterpart in low annotation regime. The proposed method is an extension of our previous work with the addition of a new unsupervised adversarial loss and a structured prediction based architecture. Though generic, we demonstrate the efficacy of our approach for retinal blood vessels segmentation from fundus images on DRIVE and STARE datasets. We experiment with extreme low annotation budget and we show, that under this constrained data setting, the proposed method outperforms our previous method and other fully supervised benchmark models. In addition, our systematic ablation studies suggest some key observations for successfully training GAN based semi-supervised algorithms with an encoder-decoder style network architecture.
@inproceedings{lahiri2020retinal,
title={Retinal vessel segmentation under extreme low annotation: A GAN based semi-supervised approach},
author={Lahiri, Avisek and Jain, Vineet and Mondal, Arnab and Biswas, Prabir Kumar},
booktitle={2020 IEEE international conference on image processing (ICIP)},
pages={418--422},
year={2020},
organization={IEEE}
}
|
|
I got this excellent website template from here. |